WORCS: A Workflow for Open Reproducible Code in Science
Why open science?
Sterling, 1959:

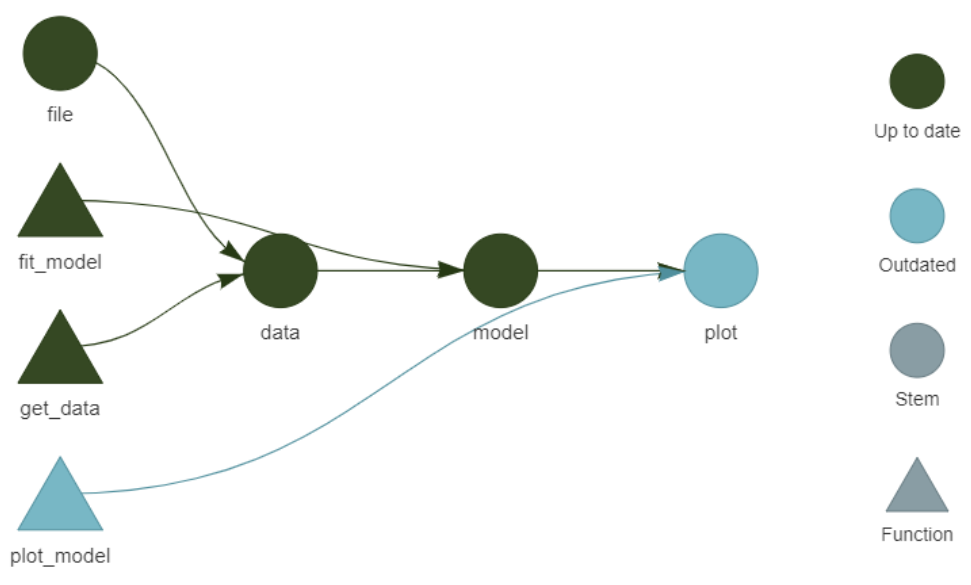
1. Dynamic document generation
- Paper consists of text and code
- Results, figures, and tables automatically generated
- Formatted as APA paper (including citations!)

Important because:
- Save time from copy-pasting output and formatting paper
- Eliminate human error in copying results;
- When revising the paper, all results are automatically updated;
- Reproducible by default: Just generate the document
R Markdown example
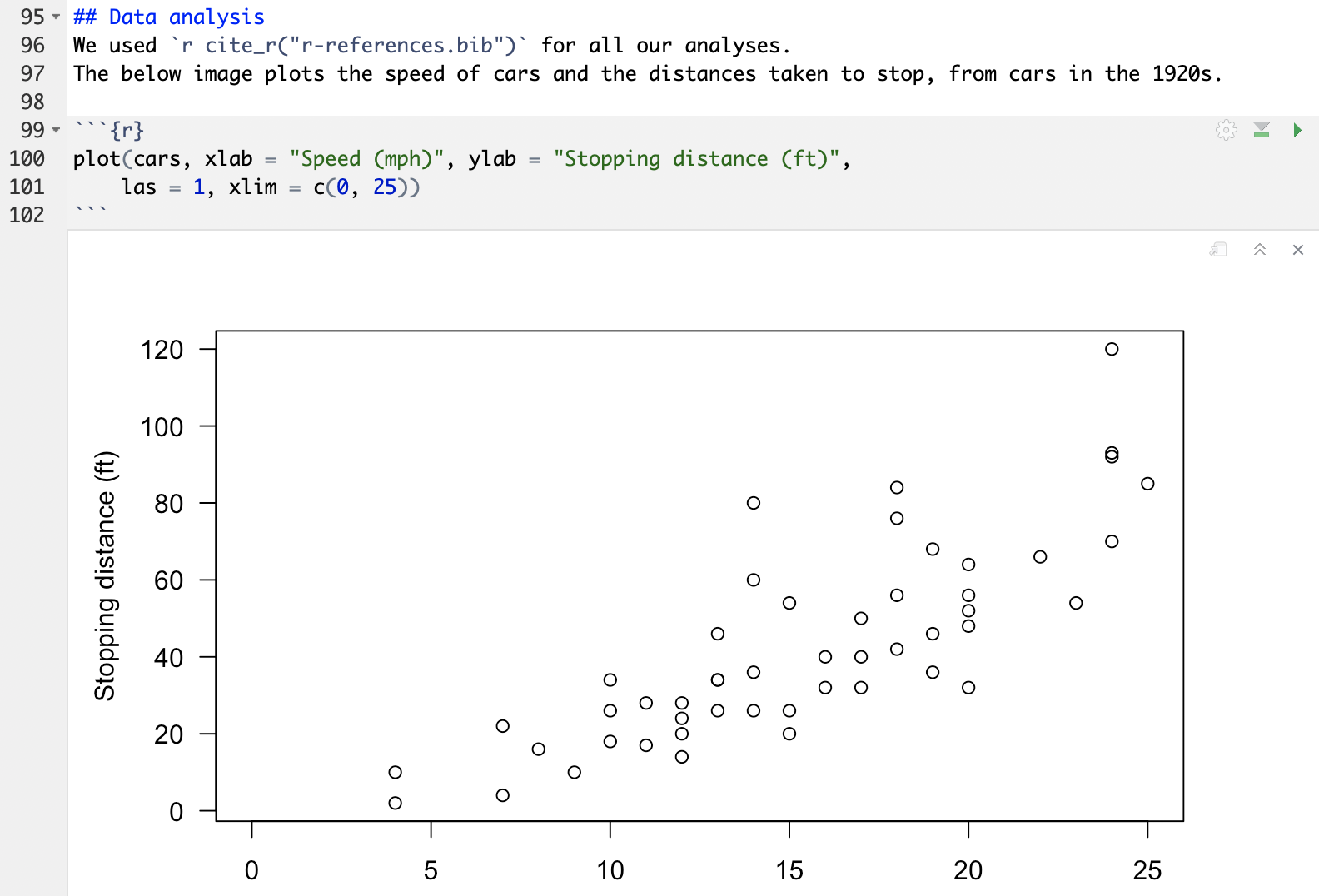
R Markdown example rendered


2. Version control (using Git)
Why version control?
NO MORE manuscript_final_final_SERIOUSLYFINAL.doc
“Track Changes” on steroids: record entire project history
If something breaks, you can figure out what happened.
Facilitates collaboration and experimentation!

2. Version control (using Git)

Tracks changes to (text-based) files line by line:
- add files to your repository
- commit changes to these files
- push all commits to remote repository (private backup or public online supplement)

One command in worcs: git_update("Describe your changes")
Image credit: Software Carpentries
Introducing GitHub
worcsrepository is backed up in a remote repository like GitHub;GitHub is a “cloud backup” with “social networking” features
- Clone other people’s repository to reproduce or build upon them
- Open Issues with questions or comments about the work
- Send suggested changes as a “Pull request”
GitHub can be used to ‘tag’ specific states of the repository, e.g. a preregistration.

3. Dependency management
- To make project reproducible, people must have access to your (exact) software dependencies
- For R-users, these are
R-packages
- For R-users, these are
- Difficult trade-off:

Dependency management in WORCS
- Maintains text-based list of packages, their version,
and origin (e.g., “CRAN”, “Bioconductor”, “GitHub”) - This list can be version-controlled with Git;
- When a user loads the project,
renvinstalls all dependencies from the list
Important because:
- Essential for reproducibility
- Good for collaboration (everybody has same versions)
- Nice to your “future self”: Your code will work in the future
![]()
Integration Testing in WORCS
worcs provides functionality for integration testing research code
Key Concepts: Define an entry point, endpoint(s), and a recipe to get from the entry point to the endpoint(s).
- Example:
- Entry point:
manuscript.Rmd - Endpoint:
manuscript.pdf - Recipe:
rmarkdown::render("manuscript.Rmd")
- Entry point:
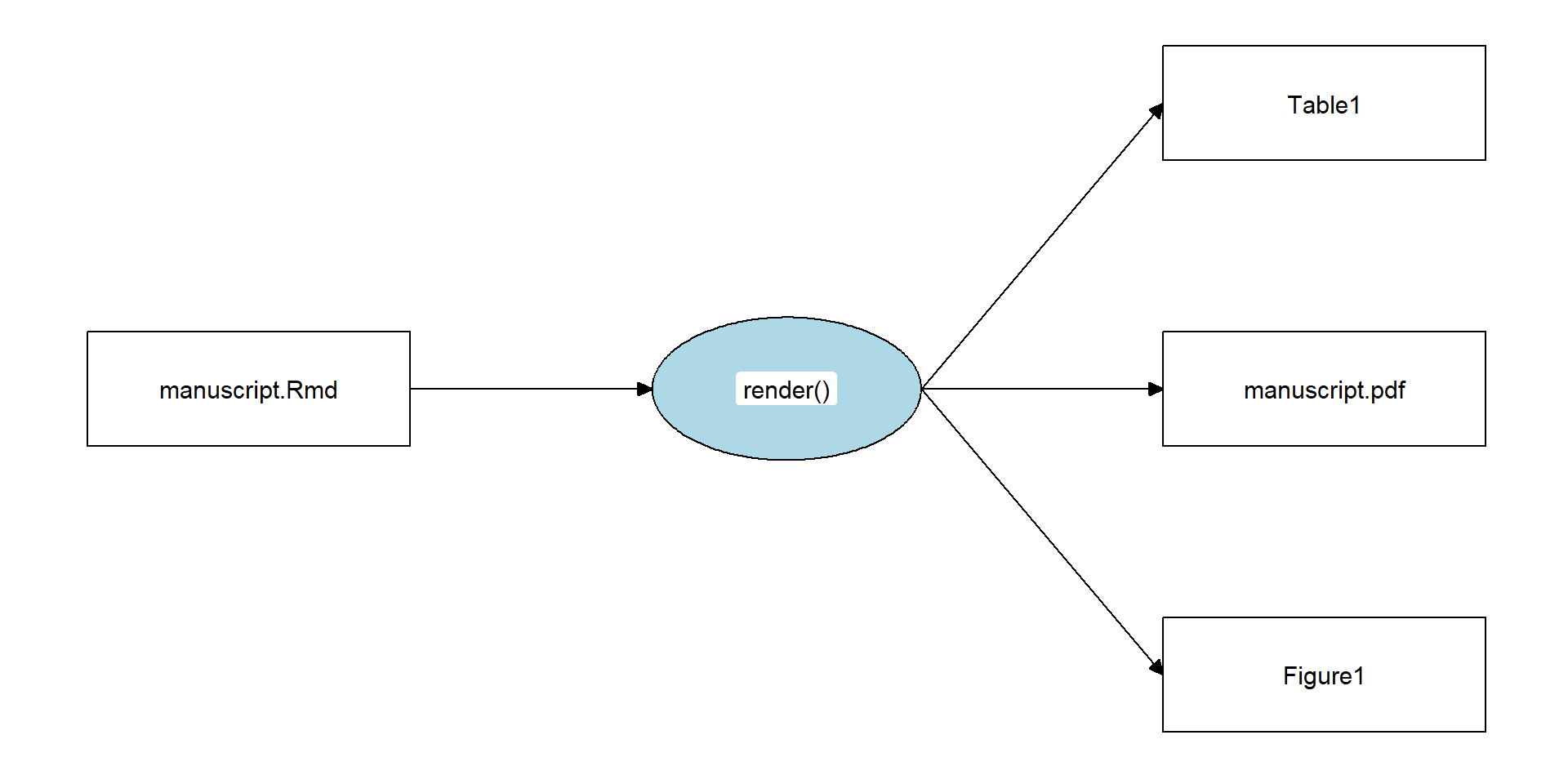
GitHub Actions
worcs::reproduce() on GitHub via GitHub Actions:
Example Pipeline