| Hours | Grade |
|---|---|
| 5 | 3 |
| 15 | 9 |
| 12 | 6 |
| 5 | 1 |
| 19 | 10 |
5 Bivariate Descriptive Statistics
In the previous chapter, we covered univariate (= single variable) descriptive statistics. In this chapter, we introduce the first bivariate (= two variables) descriptive statistics. Let’s take stock of the road so far, and set a goal for where we want to go. Last week, we ended with the variance. The variance is a statistic that tells us, on average, how much people’s scores deviate from the mean. Today we will move into bivariate descriptive statistics. We will learn about the covariance, which tells us: If someone’s score on one variable deviates positively from the mean, is their score on another variable also likely to deviate positively from the mean? We will also learn about the correlation, which tells us: How strong is the association between two variables, and is it positive or negative?
In this chapter, we will talk about two hypothetical variables, X and Y. In your mind, you can substitute any two variables you like; for example, X = hours studied, Y = grade obtained, or X = extraversion, Y = number of friends.
Before arriving at the correlation coefficient, statisticians often begin with covariance—a preliminary measure of how two variables vary together. Covariance reflects direction: it is positive when high values of X accompany high values of Y, and negative when they move in opposite directions. However, its numerical value is not directly interpretable because it is tied to the units of the measurement. A covariance expressed in centimeters and kilograms will differ from one computed in meters and pounds, even if the underlying association remains unchanged. As a result, covariance cannot meaningfully convey the strength of a relationship—only whether the variables tend to move in the same or opposite directions.
It provides a concise summary of the association between pairs of scores across individuals. For example, a researcher might retrieve each student’s high school GPA (a measure of academic performance) and pair it with their family’s annual income. The goal is to determine whether higher grades tend to correspond with higher income. In correlational studies, each individual contributes two measurements, commonly referred to as X and Y forming the foundation for analysis.
The correlation coefficient is a statistic that quantifies the strength and direction of association between two variables. It tells us the degree to which two variables move together. One way to think of the correlation coefficient is as a bivariate (= two variables) descriptive statistic.
To explore this relationship visually, researchers often rely on scatter plots. In a scatter plot, X values appear along the horizontal axis and Y values along the vertical. Each point on the plot corresponds to one participant’s pair of scores. These plots allow immediate detection of linear trends, and outliers—patterns that may remain obscured when examining data in purely numerical or tabular form.
5.0.1 Covariance
The word “covariance” means: varying, or moving, together. Let’s have a look at mock data from five students on hours studied and final grade obtained:
We can visualize these data using a “scatterplot”; a simple graph where each observation is shown as a dot with X-coordinate determined by their value on the X variable (Hours), and Y-coordinate determined by the Y variable (Grade):
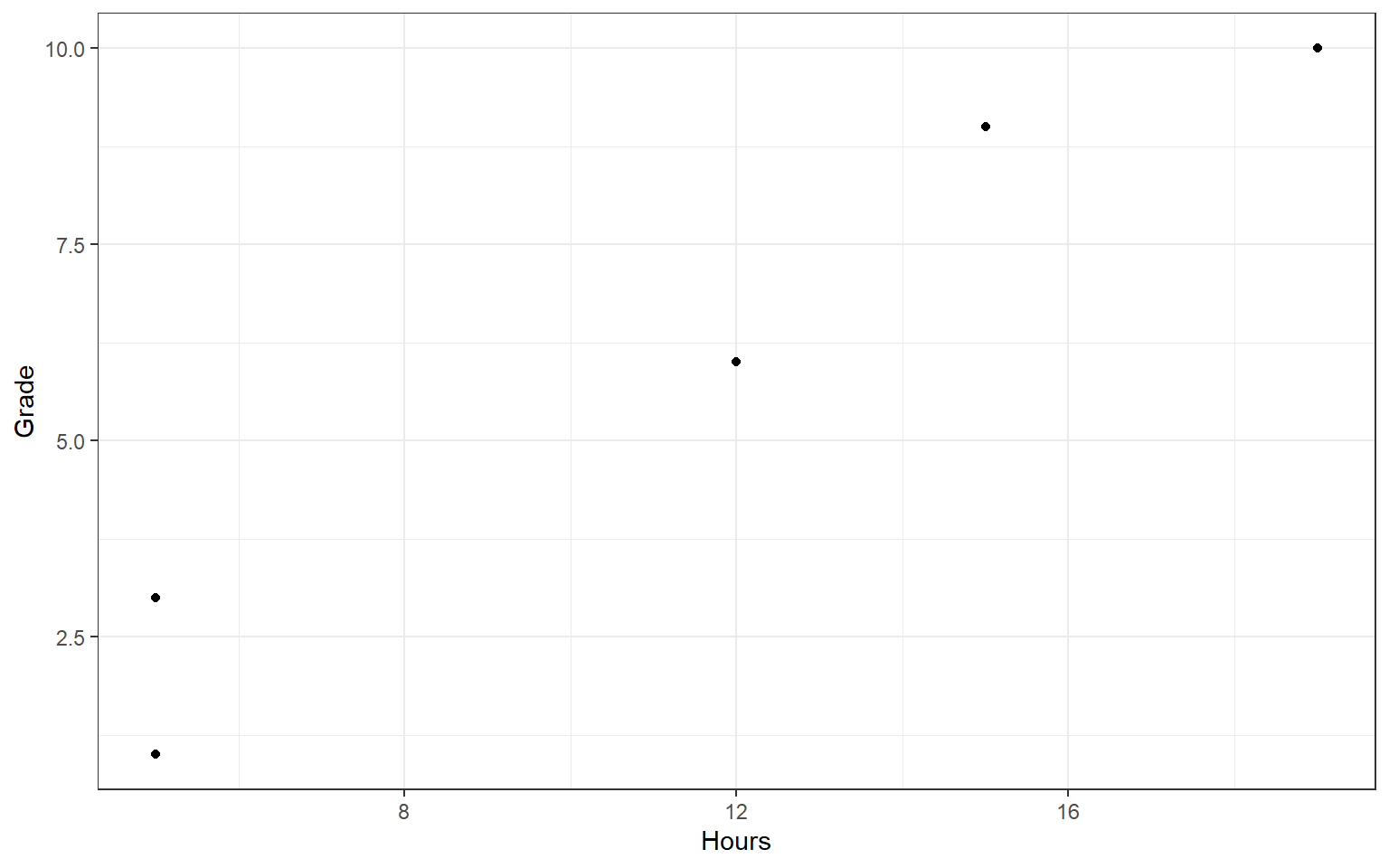
Notice that, if you squint, it appears like there might be some pattern in the data: more hours studied tends to go hand in hand with a higher grade. There might be a positive association between these variables! In the next sections, we go about quantifying this association numerically, step by step.
5.0.2 Sum of Products (SP)
The first stage in quantifying the association between two variables is to compute the sum of products of deviations (SP). The SP is similar to the sum of squares (SS), but whereas the SS captures the variability of one variable, the SP measures how two variables vary together.
To calculate the SP, take the following steps:
5.0.2.0.1 Step 1: Calculate the variables’ means
Take the mean of each column (bold in the table below):
| X | Y |
|---|---|
| 5 | 3 |
| 15 | 9 |
| 12 | 6 |
| 5 | 1 |
| 19 | 10 |
| 11.2 | 5.8 |
5.0.2.0.2 Step 2: Calculate Deviations
For each variable, calculate the deviations by subtracting the mean from the observed scores:
| X | Y | X-mean(X) | Y-mean(Y) |
|---|---|---|---|
| 5 | 3 | -6.2 | -2.8 |
| 15 | 9 | 3.8 | 3.2 |
| 12 | 6 | 0.8 | 0.2 |
| 5 | 1 | -6.2 | -4.8 |
| 19 | 10 | 7.8 | 4.2 |
5.0.2.0.3 Step 3: Multiply Deviations
If we were to calculate the SS, we would now square the deviations and add them up in each column. To get the SP, instead of squaring the deviations - we multiply them across variables. Note that if the deviations for both variables have the same sign, then this will give a positive result (positive times positive is positive, and negative times negative is positive too). Moreover, if the deviations from both variables are high, the product will be a high number too. So the SP tends to be a large positive number if high positive (or negative) deviations on one variable go hand in hand with high positive (or negative) deviations on the other variable.
| X | Y | X-mean(X) | Y-mean(Y) | Product |
|---|---|---|---|---|
| 5 | 3 | -6.2 | -2.8 | 17.36 |
| 15 | 9 | 3.8 | 3.2 | 12.16 |
| 12 | 6 | 0.8 | 0.2 | 0.16 |
| 5 | 1 | -6.2 | -4.8 | 29.76 |
| 19 | 10 | 7.8 | 4.2 | 32.76 |
Now, we calculate the SP just by taking the sum of the column of products: 92.2.
Note that if the SP is positive, then there is a positive association between the variables; if it is negative, there is a negative association. In this case, the association is positive.
Here is a formula describing what we just did: we took the sum \(\Sigma\) of the product \(()()\) of the deviations of X from the mean of X, \(X-\bar{X}\) times the deviations of Y from the mean of Y, \(Y-\bar{Y}\):
\[ SP = \sum \bigl(X - \bar{X}\bigr)\bigl(Y - \bar{Y}\bigr) \]
5.0.2.1 Covariance
To get the covariance from the sum of products, we divide by the sample size, so in this case, \(\frac{92.2}{5}\).
Another way to think about this is: we standardize the SP by the sample size \(n\). This gives us the “average co-deviation” per participant. That number is called the covariance.
If the covariance is positive, there is a positive association between the two variables. If it is negative, there is a negative association.
But how strong is the association? It is hard to say, because the size of the covariance depends on the units and scale of the two variables involved.
5.0.3 Correlation
To answer the question of how strong the association is, we must standardize the covariance to drop the units of both variables. This gives us the so-called Pearson correlation coefficient (r). Specifically, the covariance is divided by the product of the standard deviations of X and Y. This standardization results in a number between -1 and +1, where 0 means no association, -1 means perfect negative association, and +1 means perfect positive association. This number, the correlation coefficient, tells us both the direction (-/+) and strength (value) of association between two variables. Because the correlation coefficients is unit-free, or standardized, it can also be compared across variables measured on different scales and across studies.
5.0.4 Limitations
While correlation coefficients are useful, they must be interpreted with care.
To illustrate the limitations of correlations, the statistician Anscombe (1973) created four data sets with identical correlation coefficients, \(r = 0.82\). When plotting the data, however, it becomes clear that the correlation coefficient can only be meaningfully interpreted for the first dataset (figure a below).
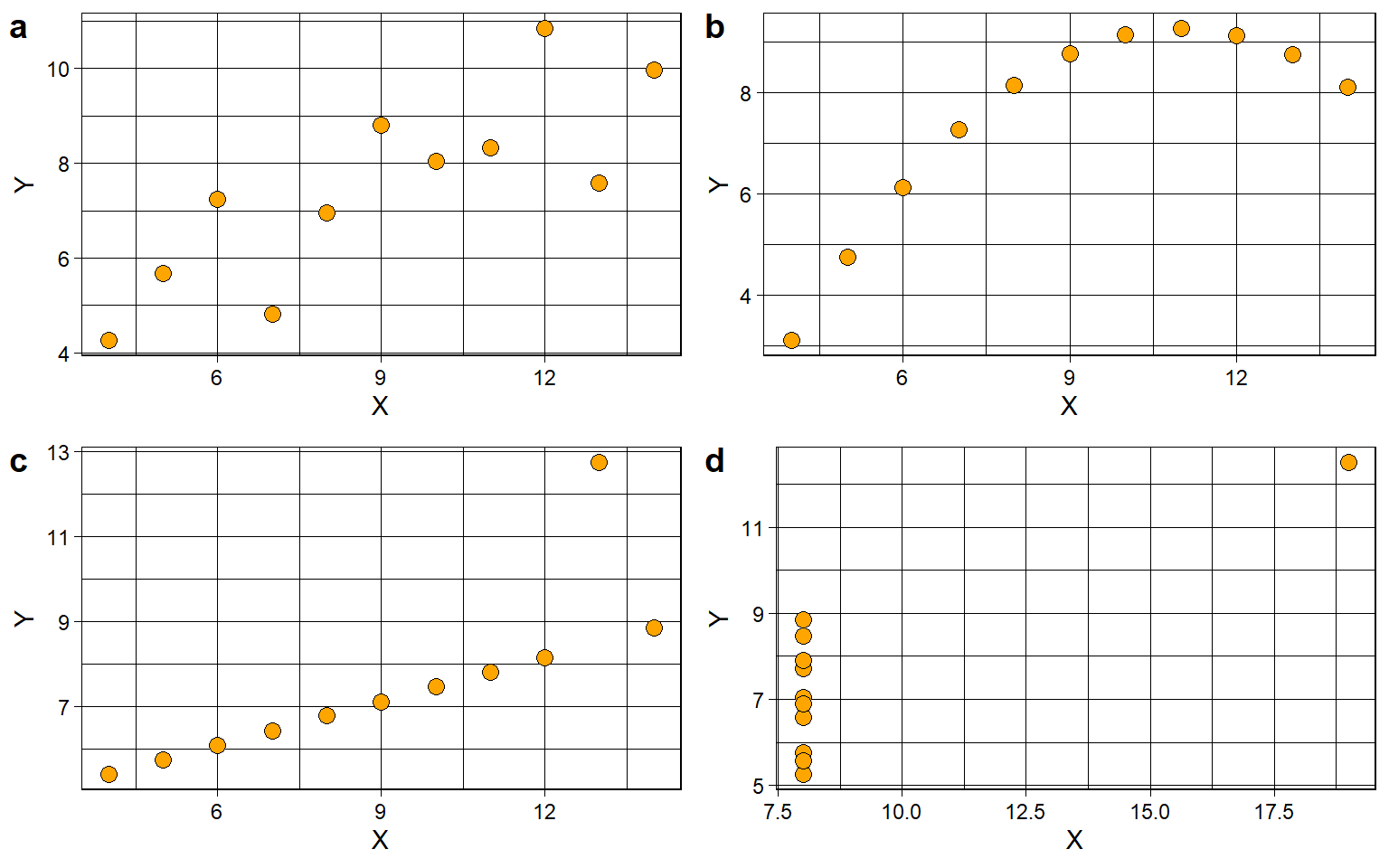
The first and most important limitation is that, Pearson’s correlation coefficient only meaningfully captures linear associations, or: patterns that look like a straight line. Note that figure a in Figure 5.1 shows such a linear pattern of association; the correlation coefficient of \(r = .82\) tells us that there is a strong - but not perfect - positive association.
Figure b in Figure 5.1 , on the other hand, shows a perfect non-linear association. All dots are perfectly in line; the line is just not straight. This illustrates that Pearson’s correlation coefficient is not suited for capturing non-linear patterns, even if a strong relationship exists in another form.
Figure c shows a correlation of \(r = 1\) for most of the points - but one outlier brings it down to \(r = .82\).
Figure d shows no association at all for most of the points (they all have the same value for X, and if X does not vary, it cannot covary/correlate with Y) - but a single outlier makes it look like there is a strong correlation..
Secondly, these plots illustrate that outliers can have a disproportionate impact. In figures c and d, a single extreme observation artificially deflates (c) or inflates (d) the correlation coefficient, potentially leading to misleading conclusions.
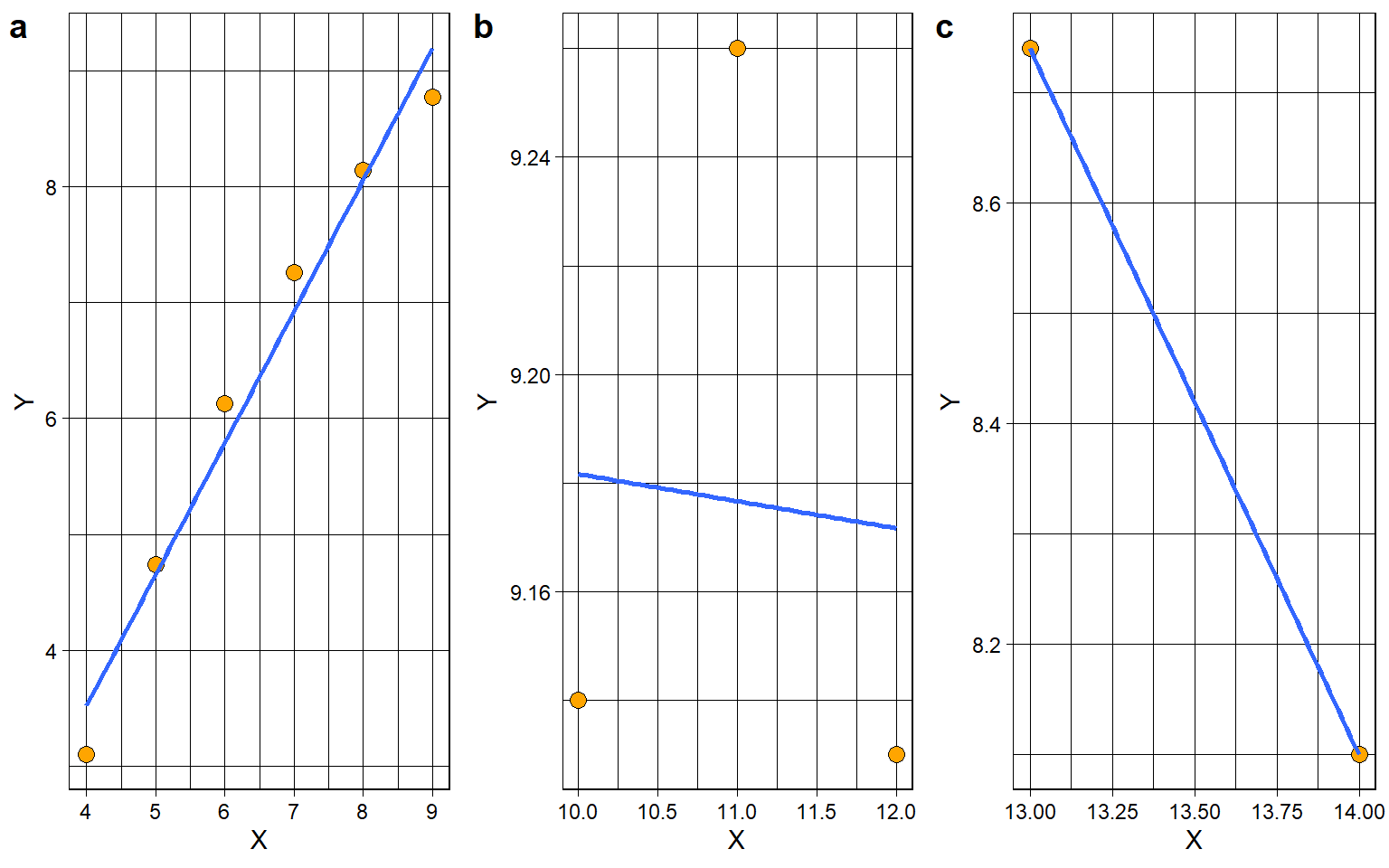
Thirdly, a restricted range of scores can obscure or distort relationships. For example, if you were to examine the pattern in figure b of Figure 5.1 for values of X between [4, 9], you would conclude that \(r = 0.99\), or near perfect positive correlation. If you examined the same pattern for values of X between (0, 13), you would conclude that \(r = -0.07\), or near-zero. If you examined the same pattern for values of X between [13, 20), you would conclude that \(r = -1.00\), or perfect negative correlation. Figure Figure 5.2 below zooms into the pattern from figure b, by restricting the range of variable X into three segments:
Restriction of range can easily happen in real life. For example, if your sample only consists of university students, you will probably have restriction of range on IQ.
Finally, you may have heard the phrase correlation does not imply causation. Observing a strong association between two variables does not mean that one causes the other. In general, it is not possible to conclude causality from statistics: causality is an assumption, which can be either supported by a theory, or by a particular methodology. In a randomized controlled experiment, participants are randomly assigned to receive either a treatment or control condition. Thus, any differences between the two groups should be due to the experimental treatment, or random chance. We will revisit the topic of causality later.
Anscombe’s quartet is a good illustration of the limitations of causality, and also demonstrates the value of visually inspecting your data (including with scatter plots) before interpreting any statistics.
5.0.5 Summary
In summary, covariance offers an initial metric for gauging whether two variables tend to vary in the same or opposite direction. However, because its magnitude depends on the measurement units of the variables involved, it cannot be directly interpreted in terms of strength. The Pearson correlation coefficient (r) addresses this limitation by standardizing the covariance, yielding a unit-free statistic bounded between –1 and +1. This standardized measure expresses both the direction and strength of a linear relationship, enabling meaningful comparisons across contexts. Nevertheless, interpreting correlations requires caution, particularly with respect to restricted sampling ranges, the influence of outliers, and the fundamental distinction between correlation and causation.
5.1 Lecture
5.2 Formative Test
This short quiz checks your grasp of Chapter 3 – Covariance & Correlation.
Work through it after you’ve studied the lecture slides (and before the next live session) so we can focus on anything that still feels uncertain. Each incorrect answer reveals a hint that sends you back to the exact slide or numerical example you need.
Question 1
A covariance of +120 cmkg tells you…Question 2
If the covariance between study hours and stress level is negative, what does that imply?Question 3
Which statement about covariance magnitude is true?Question 4
Converting temperatures from Celsius to Fahrenheit will make the covariance between temperature and ice-cream sales…Question 5
Pearson’s r is best described as…Question 6
If r = 0, we can conclude that…Question 7
A positive covariance but r ~= 0.05 usually indicates that…Question 8
Which scatterplot feature primarily determines the sign of covariance (and r)?Question 9
You multiply every X score by 10 but leave Y unchanged. What happens?Question 10
A covariance of 0 implies that…Question 11
Two variables show r = 0.85. Which conclusion is justified?Question 12
Analysing data with a restricted range typically makes r…Question 13
An extreme outlier that follows the overall trend will most likely…Question 14
A coefficient of determination (r2) of 0.49 means that…Question 15
After converting both X and Y to zscores, the covariance of those zvariables equals…Question 1
Positive sign = same-direction movement; magnitude is unit-dependent so strength not directly interpretable.
Question 2
Negative covariance means high X pairs with low Y and viceversa.
Question 3
Rescaling either variable rescales covariance; therefore magnitude alone is not comparable across units.
Question 4
Multiplying Celsius by 1.8 and adding 32 rescales covariance by 1.8; adding a constant does not affect it.
Question 5
Dividing covariance by the product of SDs removes units and bounds the result between -1 and +1.
Question 6
r only detects linear association; other patterns may still exist.
Question 7
Small r means weak linear association despite positive sign.
Question 8
Positive slope -> positive sign; negative slope -> negative sign.
Question 9
Scaling one variable scales covariance by that factor but leaves r (unitfree) unchanged.
Question 10
Zero covariance means no linear comovement; nonlinear links could still exist.
Question 11
Correlation quantifies association but cannot establish causality without experimental control.
Question 12
Less variability reduces covariance relative to the SDs, shrinking r.
Question 13
Trendconsistent outliers add leverage, increasing |r|.
Question 14
r2 translates correlation into varianceexplained terms.
Question 15
Standardising divides by SDs, so covariance in zspace equals r.
5.3 Tutorial
5.3.1 Load Data
Open LAS_SocSc_DataLab2.sav.
The file contains six variables (X1 … X6). You’ll inspect three bivariate relationships.
5.3.1.1 Plot the pairs
Generate three simple scatterplots:
-
Graphs›Legacy Dialogs›Scatter/Dot► Simple Scatter
- Pairings & axis order
-
X1(X-axis) vsX2(Y-axis)
-
X3(X-axis) vsX4(Y-axis)
-
X5(X-axis) vsX6(Y-axis)
-
- Paste and Run each syntax block.
Describe linearity, direction, and strength for each plot.
“The relationship between X1 and X2 is positive.”
“The relationship between X5 and X6 is positive.”
“The relationship between X1 and X2 is linear.”
“The relationship between X3 and X4 is linear.”
Strength of X1–X2:
Strength of X3–X4:
Strength of X5–X6:
5.3.1.2 Correlation coefficients
Even when the pattern is non-linear it’s useful to see why Pearson r can mislead.
Analyze › Correlate › Bivariate
Select all six variables → OK.
X1–X2 correlation:
X2–X6 correlation:
X3–X4 correlation:
Can we interpret X3–X4’s r at face value?
Interpret X5–X6:
Take-away: Pearson’s r is good at detecting linear patterns (like X1–X2), but it may be close to zero even when the variables have a strong curved pattern (like X3–X4).
5.4 Correlation – Work Dataset (Work.sav)
Having practiced on simulated data, let’s now apply the same workflow to a real dataset related to the workplace.
Data File: Work.sav
5.4.0.1 Why inspect the plot first?
Before trusting Pearson r we check for
- an approximately linear pattern, and
- extreme values that could distort the statistic.
Select the correct reason:
5.4.0.2 Create the scatter-plot
Graphs › Legacy Dialogs › Scatter/Dot → Simple Scatter
- X-axis =
scmental(Mental Pressure)
- Y-axis =
scemoti(Emotional Pressure)
Paste and Run.
The cloud of data points is roughly linear:
There are obvious outliers:
Approximate strength:
5.4.0.3 Compute Pearson r
Analyze › Correlate › Bivariate → (scmental, scemoti) → OK
The correlation coefficient is (2 decimals):
Interpretation:
Take-away: Mental and emotional pressure show a moderately strong, significant positive relationship—employees who feel more mentally pressured also tend to feel more emotionally pressured.