Chapter 21 Week 4 - Class
You will continue with the analysis of the Social Rejection data from the Take Home exercise. Instead of running the model as a regression model with dummy variables (as in the Take Home exercise), in lavaan you can also run the model as a regression model with multiple groups. So, when you have data with categorical and continuous independent variables, as in the data file SocialRejection.sav, you could either perform:
- an ANCOVA in R
- a regression analysis with dummy variables (in R or lavaan)
- or you could perform a multiple group analysis in lavaan.
The advantages of performing a multiple groups analysis in lavaan in this situation are:
- You can allow for differences in the (residual) variances across the groups (= violation of assumption of homogeneity)
- You can more easily test the assumption of homogenous regression lines
In a multiple group analysis you specify one model and test whether this model is correct for all the groups, or whether there are differences between the groups.
21.0.1 Specify basic model
First, specify the following model as a text string, so you can later use it in lavaan:
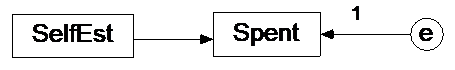
Click for explanation
reg_model <- "Spent ~ SelfEst"21.0.2 How to run multi-group model
To run this model as a multi-group model, you can specify the argument group = when running the analysis:
library(lavaan)
multi_group <- sem(reg_model,
data = data,
group = "Condition")Now, obtain the standardized estimates and the squared multiple correlations (r square) for this model.
Click for explanation
summary(multi_group, standardize = TRUE, rsquare = TRUE)## lavaan 0.6-9 ended normally after 53 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 9
##
## Number of observations per group:
## rejection 19
## neutral 20
## confirming 20
##
## Model Test User Model:
##
## Test statistic 0.000
## Degrees of freedom 0
## Test statistic for each group:
## rejection 0.000
## neutral 0.000
## confirming 0.000
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
##
## Group 1 [rejection]:
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## Spent ~
## SelfEst -0.449 0.145 -3.102 0.002 -0.449 -0.580
##
## Intercepts:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .Spent 11.073 2.768 4.000 0.000 11.073 2.593
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .Spent 12.108 3.928 3.082 0.002 12.108 0.664
##
## R-Square:
## Estimate
## Spent 0.336
##
##
## Group 2 [neutral]:
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## Spent ~
## SelfEst -0.495 0.214 -2.315 0.021 -0.495 -0.460
##
## Intercepts:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .Spent 9.690 4.331 2.237 0.025 9.690 2.095
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .Spent 16.874 5.336 3.162 0.002 16.874 0.789
##
## R-Square:
## Estimate
## Spent 0.211
##
##
## Group 3 [confirming]:
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## Spent ~
## SelfEst -0.617 0.137 -4.523 0.000 -0.617 -0.711
##
## Intercepts:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .Spent 10.861 2.604 4.171 0.000 10.861 2.322
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .Spent 10.812 3.419 3.162 0.002 10.812 0.494
##
## R-Square:
## Estimate
## Spent 0.50621.0.3 Question 1
Report on the parameter estimates for the three groups; i.e., the regression coefficients, the intercepts (marginal means of Spent), and the residual variances (i.e., the variances of the residuals of Spent).
Note: What’s missing from the model are the means and variances of SelfEst. That’s because any variable that is purely independent is not strictly considered to be part of the model. We can manually incorporate it into the model by estimating the intercept of SelfEst. This will make SelfEst part of the model, so we will also get its variance. You estimate the intercept of a variable by adding this code to your model:
"SelfEst ~1"21.0.4 Question 2
Which constraints would we need to impose, across the groups, in order to make this multi-group model equivalent to an ANCOVA?
Click for explanation
- Fix regression lines of the covariate to be equal across groups
- Fix residual variances to be equal across groups
21.0.5 Question 3
An ANCOVA tests whether the means of several groups on the DV (Spent) are all equal (while controlling for the covariate). What are the \(H_0\) and \(H_1\) of an ANCOVA?
Click for explanation
\(H_0\): The intercepts of Spent are all equal across groups \(H_1\): There is a difference in intercepts of Spent across groups
21.0.6 Question 4
You could test the null-hypothesis that you formulated in the previous question by imposing one more constraint across the three groups. What is this constraint?
Click for explanation
Fix all intercepts to be equal.
21.0.7 Imposing constraints
So, by putting constraints to these models, we can make the same model as an ANCOVA. In lavaan, we impose constraints by giving labels to parameters. You use c() to make a vector of labels that is equally long as the number of groups, and you can give any name to the labels. You then use the * symbol to assign it to a parameter. The syntax looks like this:
"Spent ~ c(labelgroup1, labelgroup2, labelgroup3) * SelfEst"If you use the same name multiple times, these parameters will be constrained to be equal:
"Spent ~ c(label, label, label) * SelfEst"Constraints for variances are specified similarly:
"Spent ~~ c(label, label, label) * Spent"21.0.8 Stepwise approach
If you want to add several restrictions (contraints), we can impose them all at once, or in a stepwise manner. Here, we will explain the stepwise approach. But if you know which model you want to run (e.g., an ANCOVA), you can also skip these steps and just run your final model and check if the fit is good.
First you test the model without the constraints and the next step is that you test the model with the first constraint, then a model with the first and second constraint, and so forth. These are all nested models. Give the models informative names, so you can easily compare them.
NOTE: make sure to specify increasingly more restricted models, that is, do not release restrictions once they have been imposed). So you go from completely free to most restrictive. You can compare subsequent models using chi-square difference tests (ironically, by calling the anova() function) to ensure that the constraints you imposed are tenable. Note that if the chi-square difference test is significant, this means you CANNOT impose the constraint!
In this case, we could run the following nested models:
Unconstrained model. No constraints are imposed
Model 1. Structural weights: constrain the regression coefficient across groups
Model 2. Structural residuals: constrain the variances and covariances of the residuals of the endogenous variables (here: Spent)
Model 3. Structural intercepts: constrain the intercepts of the endogenous variables across groups
We can compare two of these models using the anova() function:
anova(m1, m2)However, with more than two models, it is convenient to compare all of them at once. For this, we can use the function compareFit() from the semTools package (which you have to install):
library(semTools)
compareFit(weights = m1,
residuals = m2,
intercepts = m3)21.0.9 Question 5
Run the series of models (nested models) as described above. Compare the models and report the chi-square difference test of this comparison. Why does this test have the df it has? What is your conclusion about the constraints you imposed? What does this mean?
Click for explanation
mu <- sem("Spent ~ SelfEst",
data = data,
group = "Condition")
m1 <- sem("Spent ~ c(a, a, a) * SelfEst",
data = data,
group = "Condition")
m2 <- sem("Spent ~ c(a, a, a) * SelfEst
Spent ~~ c(b, b, b) * Spent",
data = data,
group = "Condition")
m3 <- sem("Spent ~ c(a, a, a) * SelfEst
Spent ~~ c(b, b, b) * Spent
Spent ~ c(c, c, c) * 1 ",
data = data,
group = "Condition")
compareFit(unconstrained = mu,
regression = m1,
residuals = m2,
intercepts = m3)## The following lavaan models were compared:
## unconstrained
## regression
## residuals
## intercepts
## To view results, assign the compareFit() output to an object and use the summary() method; see the class?FitDiff help page.In model 1 we constrained the regression lines to be equal across groups. In this model there is 1 regression coefficient estimated instead of 3, so the difference in df = 3-1=2. The associated chi-square is not significant Chi2(2) = 0.74, p = .69. This means that the regression lines can be considered equal across groups, and the first assumption of Ancova holds.
In model 2 we additionally constrained the residual variance of Spent to be equal across groups. In this model there is 1 residual variance estimated instead of 3, so the difference in df with the previous model is 3-1=2. The associated chi-square is not significant Chi2(2) = 1.74, p = .61. This means that the residual variances of Spent can als be considered equal across groups, and both assumptions hold.
21.0.10 Question 6
Next, compare Model 3 to Model 2. Report the chi-square difference test, what is the conclusion now? Is it the same conclusion from the ANCOVA? Report the relevant results for both the ANCOVA and the Multi-group model, compare the results. (Also think about: what would you report in an article?)
Click for explanation
Additionally constraining the intercepts to be equal across groups significantly deteriorated model fit, Chi2(2) = 7.61, p = .02. This means that the intercepts cannot be considered equal across groups. There is thus a significant difference in Spent between these conditions, controlled for Self-Esteem. In model 2 we see that, compared to the neutral condition (M = 10.27), the intercept is highest in the Rejection condition (M = 12.45) and lowest in the Confirming condition (M = 9.15).
In the ANCOVA in SPSS we saw that the effect of Condition was significant after controlling for the effect of self-esteem, F (2, 55) = 3.784, p < .05, so the amount spent differs between the three conditions. Respondents in the rejection condition spent more, than respondents in the neutral condition and the confirming condition.
The two conclusions are similar.